

此笔记目标:
记录学习大模型的开发过程
本笔记旨在对大模型原理有基础的认知
语言的规律
学习视频:https://www.bilibili.com/video/BV1Kb421z7Yh
什么是语言的规律:
本质是如何传递信息和意义
不同的语言不同的词汇都只是符号,被称为token
语言的规律蕴含在这些token的序列中
规律本质上就是理解每个token在现实中的含义以及它们以什么样的内在规律一个接一个的出现
如果使用语法训练AI有什么问题?
语法只是规定了一些基本的规则
使用语法来训练AI,机器没有理解词语以及句子意义,创造出来的句子即使符合语法也没有意义
所以语法不足于表示一个语言的本质
什么是联想模型?
每次根据前面的词来联想后面的词
看前面多少个词就是 n,称为n gram model
统计语言模型:基于某一个长度的上文,使用一种统计的方法被叫做统计语言模型
大模型核心秘密:根据上文来推测下一个词的过程
参考学习:three blue one brown 来理解 transformer的训练过程
GPT厉害的原因:
tranformer架构很厉害
大模型预测下一个词使用的上下文之前所有的词
通过这种预测下一个词的方式是怎么形成这个强大的语言规律的?
AI要预测下一个词的出现,它在学习了浩如烟海的文本中会发现下一个词可能比较合适
当样本量足够大的时候,模型就似乎学习到了规律,知道下一个词应该是什么,似乎它学会了某种规律
正确接话尾这个任务,它蕴含了词语的含义,对于整个句子的语法以及它在整个文化世界中的含义里是否合理的深刻理解。
大模型见多识广,知道前面的语境,后面往往会跟着什么样的词语。
大模型通过学习预测下一个词变极为深刻的洞察了人类语言的规律。(牛逼!!!)
自回归生成:把前面的输出作为条件生成下一个词
大模型理解语言了么?
答案是肯定,它并没有死记硬背
而是来理解了语言的规律之后,不断创造出新的内容
最关键的还是能够根据上下文来生成下一个词
Tranformer
学习视频:https://www.bilibili.com/video/BV17t4218761
transformer是如何预测下一个词的?
它不仅会注意它输出的附近的词,它还会注意输入序列当中所有的词
它会给每个词不一样的权重,权重是在训练过程中学习了大量的文本习得的
它会知道当前的词和输入序列中其他词的相关性有多强
然后专注于输入序列中真正重要的部分,即使两个词相隔很远,它依然可以捕获到他们的关系
transformer创新点:
自注意机制
位置编码
什么是位置编码:
transformer把词发送给神经网络前,除了生成向量,用一串数字表示
还会把每个词在句子的位置记录下来,也用一串数字表示
把上面两者都添加到输入序列的表示中
大模型既可以理解每次的意义又可以捕获每个词的位置
这个时候词语就可以不用按照顺序输入到神经网络中,这样能够并行训练了,大大提升效率
学习 《Attention is all you need》 论文
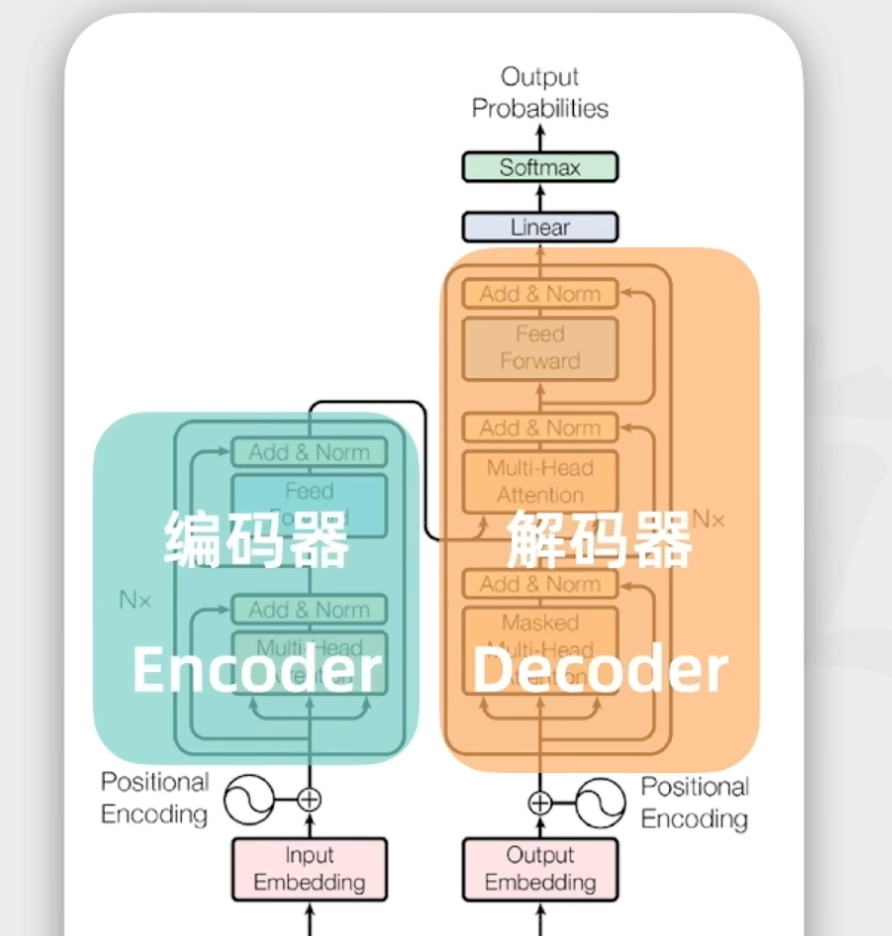
transformer组成:
编码器
解码器
工作流程:
让transformer英语翻译为法语
把英语输入到编码器中,解码器输出法语
上面的工作流程具体发生了什么呢?
编码器之前工作细节:
输入内容会被token化,把输入拆分为各个token
每个token会被一个整数表示,被称为token Id
然后把token Id 输入到嵌入层来生成向量,也是一串数字,向量的长度可以很长
为什么还需要通过向量来表示token呢?
一串数字的表示的含义是大于一个数字
能包含更多的语法语义信息
例如:男人,女人这两个词如果只用一个数字表示,那么他们的距离就很远,也可能很近
通过多个维度来表示这个token的话,更能表示这个词原来的语义
嵌入层的向量不是随便搞出来的,里面包含了词汇之间的语法语义等关系
相似的词在空间向量中也更近,没啥关系的词那么空间向量中的距离就很远
这样大模型就可以通过数学来计算向量空间里面的距离来表示词汇之间的语义以及关系!(牛逼!!!)
tranformer论文的向量长度为512,而GPT-3是12288
最后就是做位置编码,把每个token的位置信息也映射为向量,然后和前面的向量做累加发送给编码器
编码器工作细节:
把上面的输出转换为更抽象的表示形式,也是一种向量
里面保留了文本的词汇信息和顺序关系,也捕捉了语法语义的关键特征
大模型是如何捕捉关键特征的?
使用到的是tranformer的自注意力机制
模型不仅会关键自己附近的词还有关注输入序列中所有的词
计算每对词之间的相关性来决定注意力权重
如果两个词的相关性更强,那么他们的注意权重就会更高
所以上下文很重要,同一个词上下文不同就会有不同的抽象表示
tranformer 多个自注意力模块
每个头都有自己的注意权重
用来关注文本里不同特征或方面
有得关注动词,有的关注形容词
有的关注情感,有的关注命名实体
这些关注都可以做并行计算
每个自注意的权重,都是之前大模型从大量的文本里面学习的
tranformer 有多个编码器堆叠到一起
每个编码器内部结构一样,但是不共享权重
这样模型能深入理解数据,处理根据复杂的语言
解码器核心工作:
解码器是大语言模型生成一个个词的关键
解码器中接收到前面编码器的输入,之后也会经过嵌入层和位置编码层
然后被输入到多头自注意力
已经生成的序列会重新作为输入
解码器也是多个堆叠到一起的
解码器的最后还有一个线性层和Softmax层
把解码器的输出表示转换为概率分布
代表的是下一词被生成的概率分布
所以解码器本质上就是在猜下一个词的输出
解码器会重复执行多次上面的流程,直到遇到结束token
tranformer的变种
仅编码器
例如BERT
用于掩码语言建模、情感分析等
仅解码器
GPT-2,GPT-3
用于文本生成
编码器-解码器
T5、BART
用于翻译、总结
ChatGPT训练
训练GPT过程:
无监督训练
通过大量的文本无监督学习
得到一个基座模型
监督微调
通过学习人类撰写的高质量对话数据
对基座模型进行微调,得到一个微调模型
此时模型除了续写文本也具备更好的对话能力
训练奖励模型+强化学习训练
用问题和多个对应回答的数据,让人类进行质量排序
然后让这些数据训练一个评分的奖励模型
更加详细的训练步骤:
无监督训练:
输入海量互联网文本,大概3000亿Token
自己在没有标签的数据上训练
自己找出数据中的结构和模式
监督训练:
模型接收的是带有标签的数据
每个训练数据点既包括输入特征也包括输出的期望值
训练完成之后对问题根据擅长对问题做出回答
强化学习:
让上面的微调模型进行强化学习
微调模型给出答案,环境给出反馈
让人类标准员针对回答打出分数
人类打分太慢了,所以人类基于已经标注好的回答训练出来一个评分检测的奖励模型
通过奖励模型去预测回答的评分
见过一轮又轮的迭代后,模型回答的质量就会进一步提升